Stewart Dickson MathArt.com 4808 Hogan Drive Wilmington, DE 19808 dickson@mathart.com June 26, 1996
A Regenerative, Internet-Driven
Philosophical Engine
This is a continuation of work presented at the 1992 Third Inter-Symposium on Electronic Art - ISEA 1992 (TISEA) [1]. The present paper will show the first implementation of a visual dictionary, which is driven by the collaborative, interactive philosophical universe of the Internet World-Wide Web (WWW). The Dictionary server is intended to be a semi-intelligent autonomous agent, and a base platform for creating new visual art.
The existing Internet WWW site, http://www.mathart.com has been operating since March 15, 1995.[2] Integral to the content here is a dictionary [3], implemented in a symbol-processing language, styled after Mathematica, but which will probably be eventually implemented in LISP. Two existing artworks currently use this dictionary system: MathArt Automatic Poetry [4], which demonstrates semantic schemata [5] as poetry generators and the Oracle of MathArt FractalMUD [6], which demonstrates semantic schemata as philosophical memes. [7] [8]
Meaning in the MathArt Dictionary is established by context recognition, classification and by symbolic association of synonym and antonym definitions for each word definition. Grammatical structure is maintained by the symbolic dictionary word entries and by the tree structure of the database. Associated with each word are also Multimedia Internet Mail Extension (MIME) [9] data types (image, animation, sound, 3-D object, etc), recorded by Internet Uniform Resource Locator (URL).
Associating MIME type objects with words in the dictionary is essential to the concept presented in this paper: We are now able to expand the language of person-to-person, two-way communication from a 1-1/2-dimensional system of alphabetic symbol strings to a 2-1/2 dimensional system of image (and/or audio) ideograms. We have long been bombarded by the informational fire hose of quick-cut broadcast video or hypertext. Here I will demonstrate a way to talk back in the same language.
In this paper, I will demonstrate the Internet interface to the MathArt Visual Dictionary. The dictionary consists of 1,404 words and 463 images as of the time of this writing, but it is designed to be self-expanding, driven by user interaction from the Internet. The system is also designed to be network-extensible by supporting WWW HyperText Transfer Protocol (HTTP) [10] conventions.
The word and image definitions in the Dictionary and the semantic schemata used by MathArt Automatic Poetry and the Oracle of MathArt FractalMUD are memes (molecular, philosophical "genes") which are subject to selection and genetic evolution as the system develops.
In http://www.mathart.com, I have created an interactive, collaborative site which harnesses the power of the Internet as a universe of philosophical discourse. I have harnessed this power to construct a regenerative system designed to automatically create multimedia statements which have meaning and importance to the audience participating in the site.
The dictionary server at http://www.mathart.com further serves as the translative hub for a system of two-way, real-time, conversational image-based communication. I am seeking candidate beta test sites for the software server system.
This work is motivated by several observations.
The digital computer is thought to be the ultimate platform for interactive art since the "Happenings" of the neo-Dadaist Fluxus movement.
I have been creating an Internet World-Wide Web site, http://www.mathart.com since the Summer of 1994. Anonymous File Transfer Protocol (FTP) and HTTP servers log all remote user transactions. Similarly, interactive HTTP user applications collect user input of a kind totally defined by the creator of the Web site. This puts the artist in a unique and interesting relationship with his/her audience.
I have created several interactive artworks at my Web site. Two of these works utilize "Eliza" or "RACTER"-like schemantic schemata which draw from a word dictionary database system. I seek to create the highest level of sophistication in the output from these artworks that I can. I believe that the sophistication of the end-user applications are dependent upon the sophistication of the dictionary as a server system.
There are several fundamental problems to the proposition of constructing a dictionary in a computing system -- the least of which, perhaps is the size of the task in terms of the number of words which must be defined. The Internet is a global network -- not only should the dictionary I am building in my own native language be as rich as possible, I believe I should strive to support all languages in use on the Internet in my artworks.
Furthermore, human languages are not static, they are "living" entities. I have therefore chosen that my dictionary system should employ an evolutionary approach in the the dictionary database system.
Several interesting features arise out of the proposition of operating an evolutionary database system on a globally distributed, collaborative computing network: The dictionary can be self-growing -- user input can shape the definition of the words in the dictionary, and the same input can cause the scope of the dictionary to grow. In this way, I say that the system is regenerative: User input from the Internet influences the sophistication of the output the system is capable of producing. It is an active feedback loop.
There is a class of evolutionary programming in which data are viewed as evolving entities, analogous to "genes" in biological models of evolution. There is similarly a "genetic" theory of philosophy, called "memesis", in which ideas are viewed as genetic in nature.
I believe that a natural-language processing system, such as my on-line artworks, coupled to a dictionary system which functions "genetically" constitutes a testbed which will simulate or "mirror" the meme pool of popular culture on the Internet. Artworks can be constructed, which draw from the dictionary system, that will automatically satirize the ideas which served to construct the system.
The statements we are dealing with in this system need not be text-only. As I will demonstrate, I intend to utilize in this system the full multi-media power of the Internet as the next generation of electronic communication.
The success of the system depends upon the degree of sophistication that meaningful statements (termed in this paper "molecular memes") can be constructed from evolutionary "atomic" word definitions.
I have for some time recognized that there exists a gap between the conceptual foundations of my work [11] and the information which is visually apparent in the work. Mathematicians and perhaps those involved in three-dimensional computer visualization may recognize the content from the appearance of some of the works I show, but others probably do not. The MathArt Dictionary is intended to bridge this gap.
Mathematics is a universe of discourse transacted in symbolic language. It is really very general. Computer languages like Mathematica(R) [12] implement nearly the entire set of natural mathematical language - a language which pre-dates computing machinery by several thousand years. Mathematica also includes LISP-like object-oriented programming constructs which allow for extension of the language, and hence the universe of discourse.
Mathematics is the natural language of science, which is the human attempt to understand the natural world. My perception is that understanding is constructed in layers of abstraction. The most stable layers are those most closely related to observable fact. The most unstable layers occur at the fringes of knowledge and in the abstract layers we call subjective.
The MathArt Dictionary is an attempt to unify as much of human philosophy into a single, self-consistent symbol-processing system as possible. I do not believe that subjectivity is necessarily illogical or contrary to hard fact. It is merely separated by layers of abstraction -- at the boundaries of which there may be constructed consistent interfaces.
Living in our Modern, electronically mediated culture, we are in an almost constant state of information overload. Our lives are subject to enormous complexity, if not chaos. It is known that evolutionary programming [13] can be used to model extremely complex systems. For this and a number of other reasons, a I am taking a genetic approach in implementing this system.
Mathematica(R)-style symbol definitions are used in the dictionary for two reasons: 1) they are close enough to LISP-style programming to make a clean implementation in such a natural-language interpreter, and 2) to permit the eventual merging of the philosophical universe of mathematics with the more general philosophical universe of the MathArt Dictionary.
The Fractal MUD Oracle and Automatic Poetry originally employed random substitution into various semantic schemata. Semantic Schemata are grammatical skeletons which define the form of a statement. Random substitution of words into the skeletal structure by grammatical type produces results which I find amusing and it occasionally produces "gems of random wisdom". I originally built the dictionaries "by hand", which defined the scope of the universe the Oracle and poems could talk about.
I have now closed the conversational loop in my discursive system: The user can now input their own poetry, and the Graffiti received by the Oracle is now analyzed by the system and results in new semantic schemata in each area.
I have noticed that a stock photography catalogue [14] [15] is like a visual dictionary. The catalogue is categorized, with category headings denoted by image icons. But the image definitions are vague and the "dictionary" is notoriously imprecise [1].
Therefore, the MathArt dictionary also has image attachments to each database entry. These are the visual icons for the words. Visual Poetry is a first attempt at composing images which have one-to-one equivalence to abstract statements and a means of applying symbolic computation to computer image composition. The goal is to generate a correlation between natural language and compact, fully two-dimensional image symbols.
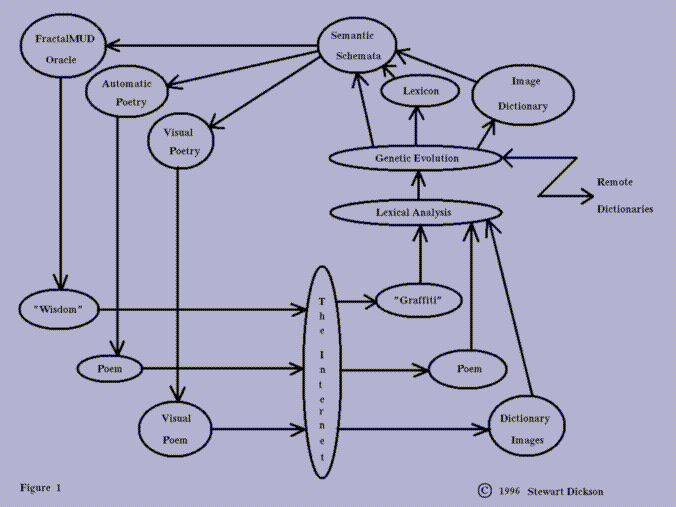
Figure 1 is a schematic diagram of how the system works for a given installed site, http://www.mathart.com, for example.
I recognized some time ago the enormous task involved in building a dictionary system capable of evolving something close to intelligible meaning. A typical human language contains approximately 80,000 words. My system is meant to harness the power of the Internet to do something it (particularly UseNet, "NetNews") is good at: developing philosophical discourse and building a universe to support it.
The dictionary system is a regenerative philosophy engine driven by the HTTP forms in FractalMUD and Automatic Poetry. Included in the figures is an HTML (HyperText Markup Language) page showing the results of a query to the dictionary from the form http://www.mathart.com/dictionary/Query.html
The lines of the dictionary entry shown in the figures are symbolic statements which are entered into the global rule base of the dictionary.
Implementing the entire administrative interface for the Dictionary in HTML opens the system up to being supported by an informal collaboration of Internet users, operating on a multitude of different networked computer platforms, guided through the process by the common HTML user interface.
The system is meant to be as simple as possible, first to support the FractalMUD Oracle and Automatic Poetry, but it is meant to be easily extensible - an open system, so that complexity may be built on top of it.
Meaning in the Dictionary is is constructed topologically - synonym and antonym entries become linkages to other words - other entries in the dictionary. The dictionary becomes a "web" of meaning. Thus, the cohesion of the dictionary is imposed by its structure, not its size. The dictionary should be fully functional at any size, and therefore scalable.
Word synonym, antonym and image URL definitions further have associated contextual tags to more finely specify the definition, to support multiple meanings for s single spelling and to glean meaning from context in the analysis of usage.
There is also a Classification database associated with the Dictionary and an interactive Classification Editor which may be used to determine the classification of a word when entering its definition.
The dictionary is currently being built primarily in English, the author's primary, native language, but it is designed to support multiple languages.
The key to building the dictionary is to give the user a means of communicating - through the input of poems and Graffiti, and through other Internet client applications which use the Dictionary server. The Dictionary then interprets this input. Unknown words are trapped and a fill-out form can be returned to the user who supplies the definition for the words. This form is shown in the figures.
The fill-out forms are not yet fool-proof. A brief study of discourse in NetNews will reveal the average correspondent's command of spelling and grammar. Incorrect entries can be made which tend to degrade the performance of Automatic Poetry and the FractalMUD Oracle. To combat this, I have developed some administrative tools which periodically scan the database for certain inconsistencies. Eventually, all dictionary entries should evolve memetic weights which will allow definitions to evolve toward consistency in a natural fashion.
When users enter poetry, the most common incompleteness introduced into the dictionary are verb conjugations. Since every verb generally has thirty-six modified forms, entering a new verb in the dictionary - by word uniqueness - only enters one form for that verb, leaving thirty-five forms of that verb incomplete. Attempts by a semantic schema to generate a given modified form - tense, plurality, person, etc. - for a verb which is missing the entry for that form returns a default construction, generated automatically from the word root. But these automatic constructions are subject to error in exceptions to the rules which occur frequently in English, for example. Or at best this tends to narrow the Dictionary's useful vocabulary.
There is therefore a maintenance tool which scans the dictionary for the modified forms defined in the schemata. Verb conjugation fill-out forms are then generated for verbs missing the modified forms called-for in the schemata.
Another frequent deficiency in the Dictionary are image URLs which serve as visual icons or visual definitions of the words. It is hoped that increased exposure for the Dictionary on the Internet and the development of additional spin-off applications which use the Dictionary, will improve its richness.
To my knowledge, the MathArt Dictionary contains no words which do not appear in any Webster's dictionary. This is my intent. However, I permit poetic license to construct new words for special tasks of meaning. The Dictionary is a living document of a living language. The only requisite criterion is that the word be adequately defined.
Words pertaining to parts of the human body I view as anatomical studies, and I believe they are appropriate to include as such. The image fragments I select to describe these words I choose carefully to read correctly in as wide a range of contexts as possible. I encourage similar selectivity in image contributions from the Internet.
I am against censorship in principle. Yet the construction of the Dictionary itself frames the problem in unique terms. To kill the visual depiction of certain words is nearly tantamount to eliminating words themselves from the dictionary. I believe that the images I have selected are in good taste. I avoid images of violence where possible.
If the results of the random schemata appear crude, it is because of the state of evolution of the system. As it grows, it should reach something approximating the general state of discourse on the Internet. The content of the dictionary should match the attitudes of the audience who created it.
In order to adequately deal with legislation such as the recent Communications Decency Act [16] of the United States Congress, there are defined "censorship" memes - or symbolic definitions attached to words corresponding to the Motion Picture Association of America (MPAA) rating codes. [17] These symbols are used to voluntarily restrict on the receiver's side, the transmission of image icons or words.
I have found this content filter system actually useful, when dealing with random chance, for limiting the threshold for surprise or shock during presentations of the system to potential sponsoring organizations.
Ultimately, the way the system operates, the memes should evolve toward a general consensus regarding the acceptability and appropriateness of the words and images being used.
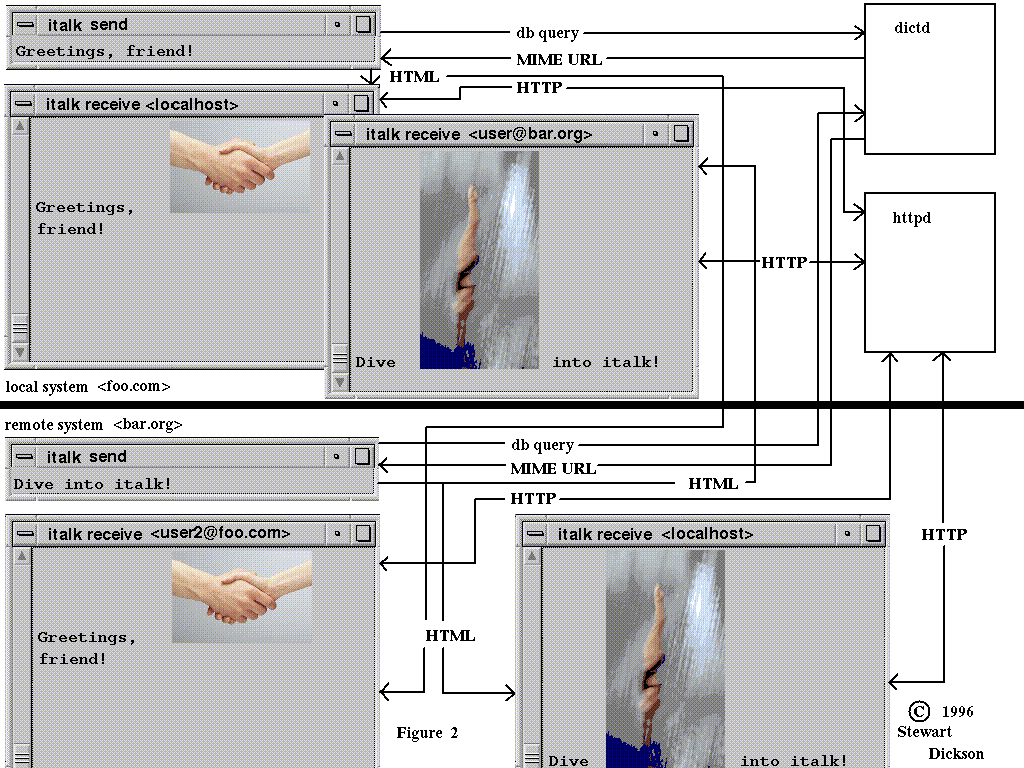
Figure 2 shows a schematic diagram of an Internet application currently written in C-language, by the author, using the X-Window system.
Called Italk ("eye-talk"), the system is patterned after the UNIX "talk" [19] user-to-user remote communication system, the "webster" Internet-based dictionary look-up system [20] and NCSA Mosaic [10].
Referring to Figure 2, the (local) user <user2@foo.com> invokes Italk given the user ID of the (remote) person <user@bar.org> with whom (s)he wants to communicate. The local user first sees the "italk send" and "italk receive <localhost>" windows appear on his/her desktop.
Like UNIX "talk", the remote user's system notifies the remote user's logged-in terminal windows that the (local) user <user2@foo.com> has requested an "italk" session. The remote talk daemon, "talkd" instructs the remote user to answer by invoking "italk user2@foo.com".
When <user@bar.org> answers, <user2@foo.com> sees a new window created on his/her desktop, titled "italk receive <user@bar.org>". <user@bar.org> sees the "italk send", "italk receive <localhost>" and "italk receive <user2@foo.com>" windows appear on his/her desktop.
Communication occurs asynchronously: Either user types into his/her "italk send" window and several things occur. The "italk send" process re-packages the input line and makes a query to the Dictionary daemon, 'dictd', of type "getURLmap[{<text ...>}]". Connection is made over Internet port 20000. [21] The Dictionary daemon returns a to the "italk send" process a list of URLs {<...>, <...>, <...>, ...} which correspond one-to-one to the words (in context) in the input text.
The "italk send" process assembles a message in HTML form using the typed words followed by their corresponding image URLs wrapped as in-lined images: <IMG SRC="http://....">. This message is sent to the "italk receive <localhost>" process for the person typing, and the "italk receive <user...>" for the person receiving. Internet port 20001 is used for "italk" messages.
The "italk receive <...>" processes on both machines parse the incoming messages, generate HTTP GET messages for each image URL and contact the appropriate HTTP daemon for the URL. As the image files are received, they are drawn into the "italk receive <...>" windows. Like NCSA Mosaic, the "italk receive <...>" processes spool images in temporary files under /usr/tmp and compose the text and images in the X "receive" windows.
Communication proceeds a line at a time, a line typed into the "send" window corresponds to a full page in the "receive" windows. The "receive" windows are redrawn and the disk caches are purged after the next line is received (assuming no images are being re-used from the last line/page).
The structure and behavior being described suggest many interesting features. It would be beneficial for dictionary daemons to eventually become as plentiful as WWW HTTP servers on the Internet. The servers to query are kept as a list in the user's Italk configuration. If for a given word an image URL is not found at one dictionary server, another is tried.
When the Dictionary server daemon receives queries for words it does not know, it compiles a list of these unknowns and does periodic queries to other peer Dictionary servers looking for definitions. A Dictionary's peer list will be updated by Italk query sessions and connections to peer dictionaries.
Italk sessions connected to each other may access different dictionaries. As shown previously, the dictionaries are more than "customizable", they are self-evolving. Different dictionaries, evolving under the influence of different user bases will reflect differing philosophical mappings of images to words.
Italk sessions connected to each other may cause the dictionaries involved communicate with each other. When this occurs, there may also be a comparison of the word-to-image mappings of the words being exchanged.
If each mapping is considered an atomic meme, there will be genetic criteria by which these memes can be exchanged when dictionaries compare database entries with each other.
Two problems can be identified in the MathArt Dictionary system, which can be characterized as problems which are fundamental to the questions of processing natural language, and attaching visual identification to elements of natural language. The first problem is establishing and recognizing word identity by usage in context, the second is identifying unique images in a networked visual library.
Several symbols are defined in the MathArt Dictionary database language which serve to construct the identity of word and image definitions -- atomic memes.
synonyms[<any_word>, "<context ...>"] := { word1, word2, ... };
antonyms[<any_word>, "<context ...>"] := { word3, word4, ... };
imageURL[<any_word>, "<context ...>"] := <http://... or /relative/path/name>;
memeWeight[word, <any_word>, "<context ...>"] := number;
memeWeight[image, <any_word>, "<context ...>"] := number;
The left-hand sides of the assignment operations uniquely identify the symbols. The right-hand sides assign value to the symbols. An attempt to re-define an existing symbol will trigger special behavior in the system. This behavior is key to the process of evolution and of maintaining consistency in the system. The robustness of atomic definitions should propagate to molecular constructions based upon them, and serve to maintain higher-level consistency.
The synonym and antonym symbols are sufficient to establish "Webster"-like definitions of the words. The trick here is selecting the defining "context" string which will be useful in identifying the word in actual usage.
The imageURL symbol is possibly a little trickier. The MIME file types, JPEG, GIF, TIFF, etc. are self-identifying objects to the extent that MIME-capable applications (Web browsers, mail readers, etc.) can decode them without user intervention. However, a system which attempts to assign contextual meaning to binary images needs more "header" information.
Identifying an image by full HTTP URL pathname is sufficient to uniquely define the identity of the image. The MathArt Dictionary database can serve as the repository for storing the definition of the image's content.
Through the memeWeight symbols, the process of entering word and image definitions into the dictionary becomes a "voting" process. This should account for subjective shades of definition, and evolve toward a consensus of definition or provide support for fine shades of meaning. The process of assigning image URLs to lines of text in 'italk' sessions then becomes one of choosing the meme with the strongest weighting for the given context. These weights can become measures of evolutionary "fitness" in subsequent genetic operations.
Establishing MathArt Visual Dictionary systems which are associated with HTTP (WWW) servers throughout the Internet will establish a networked visual library with (hopefully) well established definitions for each image.
Memetic weighting of semantic schemata is a more formidable problem. There can be deduced an aggregate memetic weight for a complete statement based upon the weights of its component memes by decomposition into "context" strings and atomic memes. The system will eventually utilize the inverse process of synthesizing new semantic structures from atomic components.
There can also be an interactive process of determining memetic value at a molecular level through literary criticism for a schema as a whole.
Another problem with the system from the point of view of an image library is the question of ownership of pictorial content. Clearly, the Networked Visual Dictionary system is intended to be either freely collaborative or totally anarchistic, depending upon one's point of view.
Ownership of the image library has been a sticking point in attempts to license the system as a whole for publication because most of the images are appropriated from unknown sources on the Internet. I have determined that the only reasonable solution is to treat the library as "freeware" separate from the server software.
Ownership of image compositions derived from applications which use the Networked Visual Dictionary is an issue subject to the same kind of debate as Pop art in collage form which consciously employs image appropriation.
The MathArt visual dictionary server is currently written in C-language. It currently loads the entire dictionary database into data structures in memory for speed in searching. Updates to the database are made first in memory then on the disk-resident version.
Contextual strings are currently defined in the parameter set in definitions of images and word synonym/antonym mappings. However, the state of development in utilizing these elements is fairly primitive at the present.
The system should re-written in LISP, or using a better natural-language processor. Under such a system, the word definitions would truly become symbolic definitions in a self-consistent, global rule base. The dictionary server daemon will then become a dynamic LISP listener which answers to Internet port 20000 instead of a terminal port. Such a system will then be able to do context-sensitive discrimination of word meaning and image mapping.
The HTML exchanged between the Italk send and receive processes is currently strictly version 2.0 or earlier. Images are composed in the receive windows in a strictly linear fashion, following the sequence of words in a statement. A more intelligent, next-generation system will be able to convert semantic context into rules of two-dimensional image composition and from them apply Netscape Navigator or HTML 3.0 extensions to the messages and compose the images into the receive window in collage form. Such a system would create parallel meaning between the image composition and the semantic context.
Furthermore, the MIME types supported in the dictionary need not be limited to two-dimensional images. Audio and animation files should be supported as well. Currently only one generic (or no particular) typeface is used in the system. Type fonts can have philosophical value assigned to them and word definitions can include context-sensitive type face references for use in composing hypertext windows.
There should be options for logging a conversation and editing it into a Quicktime or MPEG movie. This feature could be of value as a tool to video-literate artists.
Given current research in audio recognition of natural language, such as that being done by the telephone companies, one should eventually be able to interface the MathArt Visual Dictionary System to a translator which receives audio speech input and produces from it a stream of text. Here we would find a system of speaking in compact, two-dimensional symbolic ideograms directly from our voices. We could open our mouths and pictures could come out.
The method currently used for adding images to the dictionary server's library is by referencing a static URL or by submitting binary image files through a hot-link to an anonymous FTP URL which is on the server machine. (And alternately a MIME-capable "mailto:dickson@mathart.com" URL). It would be an improvement to utilize a Web browser which permits "drag and drop" uploading of images from the user's workstation to the Dictionary's library. Integration of new images into the library is either done through the network by URL reference or through the user's FTP utility. In the latter case, file naming is controlled by the FTP application.
Given MIME-capable Internet mailers, such as Zmail, some interesting extensions are possible. A user can compose MIME-enriched mail messages by feeding the output of MathArt Poetry or 'italk' text translations into his/her MIME mailer. The Dictionary server could also develop an e-mail interface extension to its query language which can directly accept MIME-encapsulated binary image data with definition references in the message body.
Similar interesting extensions would arise with a MIME-capable series of UseNet news readers and posting tools.
The concept of the Internet World-Wide Web as a huge image library should not be dismissed lightly. There could also be employed in the Dictionary Web Crawler-like autonomous discovery tools which could do lexical analysis on existing network-resident HTML in order to discover images of interest and their significance.
Given 3-D object file types, like OpenInventor, DXF, etc., applications could be created using the Virtual Reality Modeling Language (VRML) [22] instead of HTML. These applications would employ 3-D type faces and three-dimensional spatial compositional rules, and would construct virtual sculptures instead of two-dimensional image compositions.
I am packaging the MathArt Visual Memetic Dictionary system as a portable share-ware software package, which may be installed at any Internet site with a running Unix-based HTTP server and Internet Domain Name Service (DNS). I am seeking webmasters and webmistresses interested in becoming Beta testers for the system.
This paper has presented a network-accessible dictionary system in which word entries consist of symbolic definitions of string rewriting rules. I have demonstrated facilities accessible to the Internet World-Wide Web for adding entries to the dictionary and for generating poetry using skeletal semantic schemata. We have seen how MIME image file types, mapped to word definitions can result in a "semantic amplifier" in which words in a sentence are multiplied "by a thousand" by composing image icons with the corresponding words.
The HTTP interface to the dictionary results in a self-growing, regenerative philosophical system. Given typical HTTP server access statistics in the thousands per day, a networked dictionary can grow fairly quickly by an independently operating networked collective effort, compared to manual work by a single individual. The HTTP server at http://www.mathart.com recently reported 10,000 "hits" in a week, peaking at 2,000 in a single day.
In order to support such a distributed self-growth, the Dictionary has been designed to function using genetic algorithms to organize information submitted in a somewhat chaotic fashion. It is known that genetic algorithms are useful in understanding chaotic systems of extreme complexity, such as the stock market. [23] I therefore propose that the Networked, Memetic Visual Dictionary system could be applied to understanding a complex, chaotic system, such as the electronic media culture of the Internet, itself.
This paper has also presented a two-way, conversational system of communication in which words typed into an application window are transmitted to another computer user accompanied by MIME image file translations of the words. We have been bombarded by emotionally-charged image sequences in quick-cut television. Now we have the means to talk back, and to each other in the same language.
The dictionary servers accessed by those involved in Italk sessions may evolve independently and then interact with each other as Italk users interact. In this, we find a kind of mechanized philosophical "debate" taking place as the servers apply genetic algorithms to determine how image-word definitions should be updated on a given server and then from server to server.
To date, the performance of the system is still somewhat primitive. This paper presents "version 1.0" of the system. The greatest strength is the novel use of the multimedia capability of current Internet applications. As has been stated, however, the system is designed to evolve and is expected to increase in sophistication as time progresses. I believe this is now occurring in the system. To this extent the project is successful.
As in all computer simulation, the goal in this work is to construct an objective reference model with which to test the dynamics of contemporary, popular philosophy. Modern life is incredibly complex. We are usually functioning in a state of information overload. The Internet is a radical new model of electronic media in that it is interactive, and that content in this medium is available for processing by intelligent automatic agents.
It would be useful to employ the Memetic Dictionary as a testbed for examining the discourse of media. For example, the system should eventually be able to detect "bogus" information, emanating from a dangerously constricted universe of discourse, as in political propaganda or commercial advertizing for example.
Similarly, it should be possible to symbolically re-construct "corrected" versions of the original, fallacious statements to frame a more proper philosophical standpoint in terms identical to the original. Such a system could be called "memetic engineering" -- or a process of rendering harmless, or beneficial an originally "infectious" meme and re-injecting it back into the meme pool.
[1] Stewart Dickson, "Automated Fabrication as a Model for Extending the Philosophy of Visual Perception"; ISEA 1992 (TISEA).
[2] http://www.mathart.com has been plagued by availability problems related to the economic support of the site. See Edmund L. Andrews, "A Steep Hurdle to Web Shortcut," The New York Times (p. D1, "Business Monday" March 25, 1996). A high-availability mirror site, http://www.wolfram.com/~mathart has been operating since October, 1994. This site has all the front-end documentation in static HTML, that http://www.mathart.com has. Most of the interactive, database-related applications live only at http://www.mathart.com.
[3] Stewart Dickson, MathArt Visual Dictionary, http://www.wolfram.com/~mathart/dictionary/Dictionary.html
[4] Stewart Dickson, MathArt Automatic Poetry, http://www.wolfram.com/~mathart/poetry/poetry_home.html
[5] Clifford Pickover, Computers and the Imagination: Visual Adventures Beyond the Edge; New York: St. Martin's Press; 1991 (pp. 317-320). See also "Eliza" and "RACTER": Mark Kantrowitz, FAQ: Artificial Intelligence Questions and Answers, http://www.cs.cmu.edu/Web/Groups/AI/html/faqs/ai/ai_general/top.html and rtfm.mit.edu:/pub/usenet/news.answers/ai-faq/general/
[6] Stewart Dickson, MathArt FractalMUD, http://www.wolfram.com/~mathart/FractalMUD/FractalMUD_home.html
[7] Fringeware, Inc., What is Memetics? http://www.fringeware.com/HTML/memetics.html
[8] Ars Electronica '96, MEMESIS - THE FUTURE OF EVOLUTION http://www.aec.at/meme/symp/ and open-memesis@aec.at
[9]Jerry Sweet, Comp.mail.mime Frequently Asked Questions List (FAQ) comp.mail.mime, rtfm.mit.edu:/pub/usenet-by-group/news.answers/mail/mime-faq/
[10] National Center for Supercomputing Applications (NCSA), http://www.ncsa.uiuc.edu/SDG/Software/Mosaic/NCSAMosaicHome.html, University of Illinois, Urbana-Champaign (UIUC).
[11] Ivars Peterson, "Plastic Math", Science News Volume 140, No. 5, pp. 72-73, August 3, 1991.
[12] Stephen Wolfram, Mathematica, a System for Doing Mathematics by Computer, Second Edition, Addison-Wesley Publishers, 1990. See also http://www.wolfram.com
[13] Joerg Heitkoetter and David Beasley, The Hitch-Hiker's Guide to Evolutionary Computation; The Frequently Asked Questions (FAQ) document in UseNet NewsGroup comp.ai.genetic, 1994. Available via anonymous FTP from rtfm.mit.edu:/pub/usenet/news.answers/ai-faq/genetic/ About 90 pages.
[14] SUPERSTOCK, 11 West 19th Street, New York, NY 10011, USA.
[15] PhotoDisc, Inc., 2013 Fourth Avenue, Seattle, WA 98121, USA.
[16] Center for Democracy and Technology, < HREF="http://www.cdt.org/speech.html"> http://www.cdt.org/speech.html
[17] MPAA Home Page, http://www.mpaa.org, The Motion Picture Association of America, Inc.
[18] Timothy Leary, Flashbacks, Putnam Publishing Group, New York 1990, p. 156.
[19] Tracey Appleby, Harry Renshall, Judy Richards, Alan Silverman CERN UNIX User Guide Version 1.02 http://wsspinfo.cern.ch/file/doc/unixguide/unixguide.html
[20] Bennett Yee, Hypertext Webster Interface http://c.gp.cs.cmu.edu:5103/prog/webster
[21] Internet Assigned Numbers Authority (IANA), Port Numbers and Services Database, http://www.sockets.com/services.htm and http://www.isi.edu/div7/infra/iana.html
[22] Wired Magazine, "The VRML Forum",
http://vrml.wired.com/
[23] BioComp Systems, Inc.
Using Neural Networks to Predict the Financial Markets,
http://www.bio-comp.com/financia.htm
1 - Schematic Diagram of the MathArt Visual Dictionary System
Reproductions of HTML Pages from http://www.mathart.com:
"MathArt Dictionary Query Results";
"MathArt Dictionary Word Entry Form";
"MathArt Dictionary Classification Editor";
"Real-Time Poetry", http://www.mathart.com/poetry/poetry_home.html;
"Visual Poetry", http://www.mathart.com/poetry/visual_poetry.html;
"MathArt FractalMUD Oracle of FractalMUD".
ILLUSTRATIVE FIGURES
{kind=link}
{kind=link}